100 Times Faster Natural Language Processing in Python
How to take advantage of spaCy & a bit of Cython for blazing fast NLP
Published BY: Thomas Wolf
When we published our Python coreference resolution package last year, we got an amazing feedback from the community and people started to use it for many applications , some very different from our original dialog use-case .
And we discovered that, while the speed was totally fine for dialog messages, it could be really slow on larger news articles.
I decided to investigate this in details and the result is NeuralCoref v3.0 which is about 100 times faster than the previous version (several thousands words per seconds) while retaining the same accuracy, and the easiness of use and eco-system of a Python library.
In this post I wanted to share a few lessons learned on this project, and in particular:
- How you can design a high-speed module in Python,
- How you can take advantage of spaCy’s internal data structures to efficiently design super fast NLP functions.
So I am a bit cheating here because we will be talking about Python, but also about some Cython magic — but, you know what? Cython is a superset of Python, so don’t let that scares you away!
Your current Python program is already a Cython program.
There are several cases where you may need such speed-ups, e.g.:
- you are developing a production module for NLP using Python,
- you are computing analytics on a large NLP dataset using Python,
- you are pre-processing a large training set for a DeepLearning framework like pyTorch/TensorFlow, or you have a heavy processing logic in your DeepLearning batch loader that slows down your training.
First step to rocket speed: Profiling

The first thing to know is that most of your code is probably just fine in pure Python but there can be a few bottlenecks functions that will get you orders of magnitude faster if you give them some love.
You should thus start by profiling your Python code and find where the slow parts are located. One option is to use cProfile like that:
You’ll likely find that the slow parts are a few loops, and some Numpy arrays manipulations if you use neural networks (but I won’t spend time talking about NumPy here as there is already a lot of information written about that).
So, how can we speed up these loops?
Fast Loops in Python with a bit of Cython
Let’s work this out on a simple example. Say we have a large set of rectangles that we store as a list of Python objects, e.g. instances of a
Rectangle class. The main job of our module is to iterate over this list in order to count how many rectangles have an area larger than a specific threshold.
Our Python module is quite simple and looks like this:
The
check_rectangles function is our bottleneck! It loops over a large number of Python objects and this can be rather slow as the Python interpreter does a lot of work under the hood at each iteration (looking for the area method in the class, packing and unpacking arguments, calling the Python API….).Here comes Cython to help us speed up our loop.
The Cython language is a superset of Python that contains two kind of objects:
- Python objects are the objects we manipulate in regular Python like numbers, strings, lists, class instances…
- Cython C objects are C or C++ objects like double, int, float, struct, vectors that can be compiled by Cython in super fast low-level code.
A fast loop is simply a loop in a Cython program within which we only access Cython C objects.
Astraightforward approach to designing such a loop is to define C structures that will contain all the things we need during our computation: in our case, the lengths and widths of our rectangles.
We can then store our list of rectangles in a C array of such structures that we will pass to our
check_rectangle function. This function now has to accept a C array as input and thus will be defined as a Cython function by using the cdefkeyword instead of def (note that cdef is also used to define Cython C objects).
Here is how the fast Cython version of our Python module looks like:
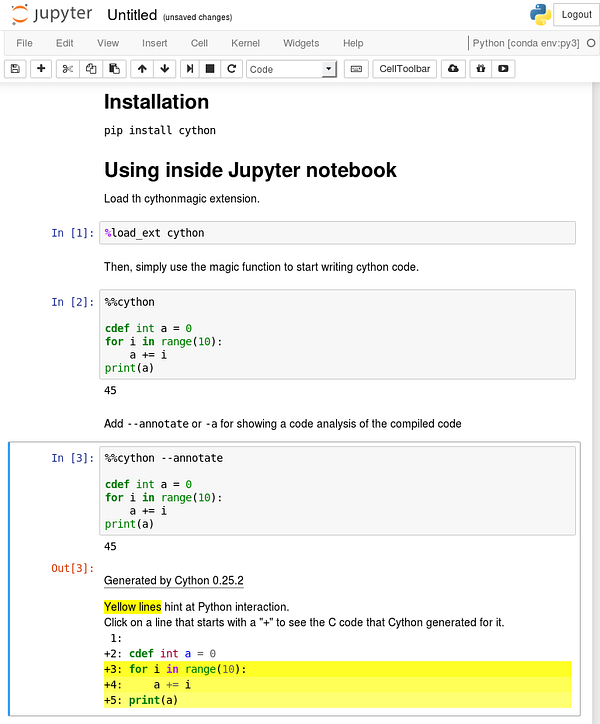
First install Cython with
pip install cythonFirst Tests in Jupyter
Load the
Cython extension in a Jupyter notebook with %load_ext Cython.
Now you can write Cython code like Python code by using the magic command
%%cython.
If you have a compilation error when you execute a Cython cell, be sure to check Jupyter terminal output to see the full message.
Most of the time you’ll be missing a
-+ tag after %%cythonto compile to C++ (for example if you use spaCy Cython API) or an import numpy if the compiler complains about NumPy.Writing, Using and Distributing Cython Code
Cython code is written in .pyx files. These files are compiled to C or C++ files by the Cython compiler and then to byte-code level with the system’s C compiler. The byte-code level files can then be used by the Python interpreter.
You can load a .pyx file directly in Python by using
pyximport:>>> import pyximport; pyximport.install() >>> import my_cython_module
You can also build your Cython code as a Python package and import/distribute it as a regular Python package as detailed here. This can take some time to get working, in particular on all platforms. If you need a working example, spaCy’s install script is a rather comprehensive one.
Before we move to some NLP, let’s quickly talk about the
def, cdef and cpdef keywords, because they are the main things you need to grab to start using Cython.
You can use three types of functions in a Cython program:
- Python functions, which are defined with the usual keyword
def. They take as input and output Python objects. Internally they can use bothPython and C/C++ objects and can call both Cython and Python functions. - Cython functions defined with the
cdefkeyword. They can take as input, use internally and output both Python and C/C++ objects. These functions are not accessible from the Python-space (i.e. the Python interpreter and other pure Python modules that would import your Cython module) but they can be imported by other Cython modules. - Cython functions defined with the
cpdefkeyword are like thecdefCython functions but they are also provided with a Python wrapper so they can be called from the Python-space (with Python objects as inputs and outputs) as well as from other Cython modules (with C/C++ or Python objects as inputs).
The
cdef keyword has another use which is to type Cython C/C++ objects in the code. Unless you type your objects with this keyword, they will be considered as Python objects (and thus slow to access).Using Cython with spaCy to speed up NLP
This is all nice and fast but… we are still not doing NLP here! No string manipulations, no unicode encodings, none of the subtleties we are lucky to have in Natural Language Processing .
And the official Cython documentation even advises against the use of C level strings:
Generally speaking: unless you know what you are doing, avoid using C strings where possible and use Python string objects instead.
So how can we design fast loops in Cython when we work with strings?
spaCy got us covered.
The way spaCy tackle this problem is quite smart.
Convert all strings to 64-bit hashes
All the unicode strings in spaCy (the text of a token, its lower case text, its lemma form, POS tag label, parse tree dependency label, Named-Entity tags…) are stored in a single data structure called the
StringStore where they are indexed by 64-bit hashes, i.e. C level uint64_t.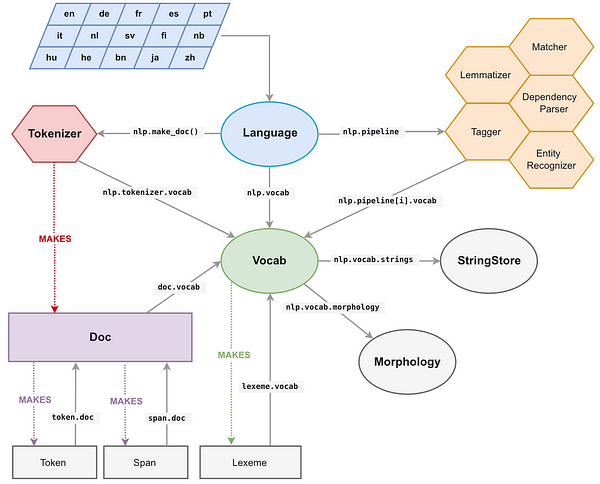
It is accessible from everywhere in spaCy and every object (see on the left), for example as
nlp.vocab.strings, doc.vocab.strings or span.doc.vocab.string.
When a module needs to perform fast processing on some tokens, it simply uses the C level 64-bit hashes instead of the strings. A call to the
StringStore look up table will then give back the Python unicode strings associated to the hashes.
But spaCy does more than that and also gives us access to fully populated C level structures of the document and vocabulary, which we can use in Cython loops instead of having to build our own structures.
SpaCy’s internal data structures
The main data structure associated to a spaCy document is the
Doc object which owns the sequence of tokens (“words”) of the processed string and all their annotations in a C level object called doc.c which is an array of TokenCstructures.
The TokenC structure contains all the informations we need about each tokens. This information is stored as 64-bit hashes that can be re-associated to unicode strings as we’ve just seen.
To see exactly what’s in these nice C structures, just have a look at the freshly created Cython API doc of spaCy .
Let’s see that in action on a simple example of NLP processing.
🚀Fast NLP Processing with spaCy and Cython
Let’s say we have a dataset of text documents we need to analyse.
A Python loop to do that is short and straightforward:
On the left I wrote a script that builds a list of 10 documents parsed by spaCy, each with ~170k words. We could also have 170k documents with 10 words in each (like a dialog dataset) but that’s slower to create so let’s stick with 10 docs.We want to perform some NLP task on this dataset. For example, we would like to count the number of times the word “run” is used as a noun in the dataset (i.e. tagged tagged with a “NN” Part-Of-Speech tag by spaCy).
But it’s also quite slow! On my laptop this code takes about 1.4 second to get the answer. If we had a million documents it would take more than a day to give us the answer.We could use multiprocessing but it’s often not such a great solution in Pythonbecause you have to deal with the GIL. Also, note that Cython can also use multi-threading! And that may actually even be the best part of Cythonbecause the GIL is released so we are at full speed 🏎 Cython basically directly call OpenMP under the hood. Now let’s try to speed up our Python code with spaCy and a bit of Cython.
First, we have to think about the data structure. We will need a C level array for the dataset, with pointers to each document’s TokenC array. We’ll also need to convert the test strings we use (“run” and “NN”) to 64-bit hashes.
When all the data required for our processing is in C level objects, we can then iterate at full C speed over the dataset.
Here is how this example can be written in Cython with spaCy:
The code is a bit longer because we have to declare and populate the C structures in
main_nlp_fast before calling our Cython function [*].But it is also a lot faster! In my Jupyter notebook, this Cython code takes about 20 milliseconds to run which is about 80 times faster than our pure Python loop.The absolute speed is also impressive for a module written in a Jupyter Notebook cell and which can interface natively with other Python modules and functions: scanning ~1,7 million words in 30ms means we are processing a whopping 80 millions words per seconds.This concludes our quick introduction on using Cython for NLP. I hope you enjoyed it.There are a lot of other things to says on Cython but it would get us too far from this simple introduction. The best place to start from now is probably the Cython tutorials for a general overview and spaCy’s Cython page for NLP.*. ^ If you use low level structures several times in your code, a more elegant option than populating C structures each time, is to design our Python code around the low level structures with a Cython extension type wrapping the C level structures. This is how most of spaCy is structured and it is a very elegant way to combine fast speed, low memory use and the easiness of interfacing with external Python libraries and functions.
No comments:
Post a Comment