Data Science Simplified Part 1: Principles and Process
In 2006, Clive Humbly, UK Mathematician, and architect of Tesco’s Clubcard coined the phrase “Data is the new oil. He said the following:
”Data is the new oil. It’s valuable, but if unrefined it cannot be used. It has to be changed into gas, plastic, chemicals, etc. to create a valuable entity that drives profitable activity; so, must data be broken down, analyzed for it to have value.”
The iPhone revolution, growth of the mobile economy, advancements in Big Data technology has created a perfect storm. In 2012, HBR published an article that put Data Scientists on the radar.
The article Data Scientist: The Sexiest Job of the 21st Century labeled this “new breed” of people; a hybrid of data hacker, analyst, communicator, and trusted adviser.
Every organization is now making attempts to be more data-driven. Machine learning techniques have helped them in this endeavor. I realize that a lot of the material out there is too technical and difficult to understand. In this series of articles, my aim is to simplify Data Science. I will take a cue from the Stanford course/book (An Introduction to Statistical Learning). This attempt is to make Data Science easy to understand for everyone.
Every organization is now making attempts to be more data-driven. Machine learning techniques have helped them in this endeavor. I realize that a lot of the material out there is too technical and difficult to understand. In this series of articles, my aim is to simplify Data Science. I will take a cue from the Stanford course/book (An Introduction to Statistical Learning). This attempt is to make Data Science easy to understand for everyone.
In this article, I will begin by covering fundamental principles, general process and types of problems in Data Science.
Data Science is a multi-disciplinary field. It is the intersection between the following domains:
- Business Knowledge
- Statistical Learning aka Machine Learning
- Computer Programming
The focus of this series will be to simplify the Machine Learning aspect of Data Science. In this article, I will begin by covering principles, general process and types of problems in Data Science.
Key Principles:
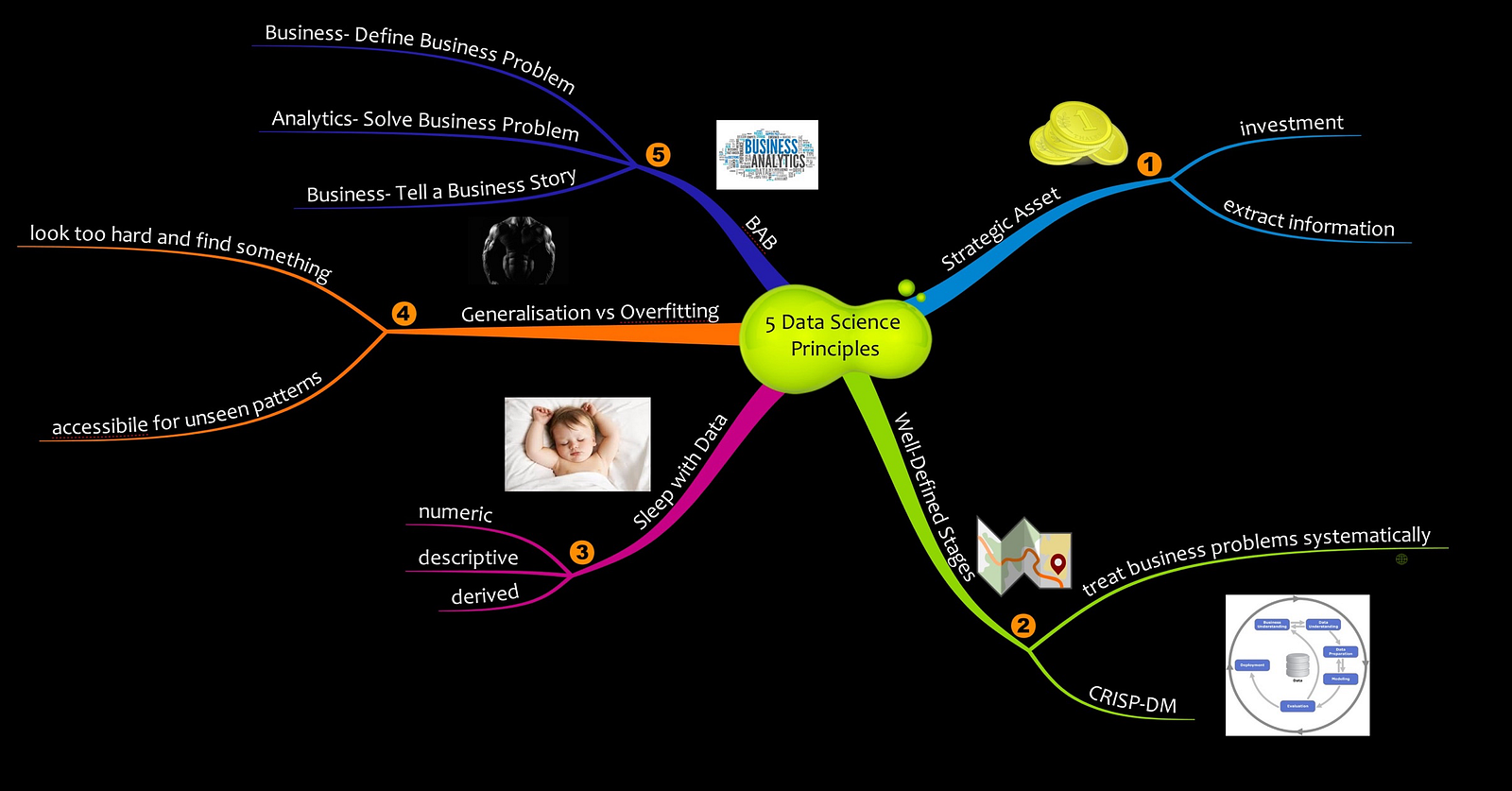
- Data is a strategic asset: This concept is an organizational mindset. The question to ask is: “Are we using the all the data asset that we are collecting and storing? Are we able to extract meaningful insights from them?”. I’m sure that the answers to these question are “No”. Companies that are cloud born are intrinsically data-driven. It is in their psyche to treat data as a strategic asset. This mindset is not valid for most of the organization.
- A systematic process for knowledge extraction: A methodical process needs to be in place for extracting insights from data. This process should have clear and distinct stages with clear deliverables. The Cross Industry Standard Process for Data Mining (CRISP-DM) is one such process.
- Sleeping with the data: Organisations need to invest in people who are passionate about data. Transforming data into insight is not alchemy. There are no alchemists. They need evangelists who understand the value of data. They need evangelists who are data literate and creative.They need folks who can connect data, technology, and business.
- Embracing uncertainty: Data Science is not a silver bullet. It is not a crystal ball. Like reports and KPIs, it is a decision enabler. Data Science is a tool and not a means to end. It is not in the realm of absolute. It is in the realm of probabilities. Managers and decision makers need to embrace this fact. They need to embrace quantified uncertainty in their decision-making process. Such uncertainty can only be entrenched if the organizational culture adopts a fail fast-learn fast approach. It will only thrive if organizations choose a culture of experimentation.
- The BAB principle: I perceive this as the most important principle. The focus of a lot of Data Science literature is on models and algorithms. The equation is devoid of business context. Business-Analytics-Business (BAB) is the principle that emphasizes the business part of the equation. Putting them in a business context is pivotal. Define the business problem. Use analytics to solve it. Integrate the output into the business process. BAB.
Process:
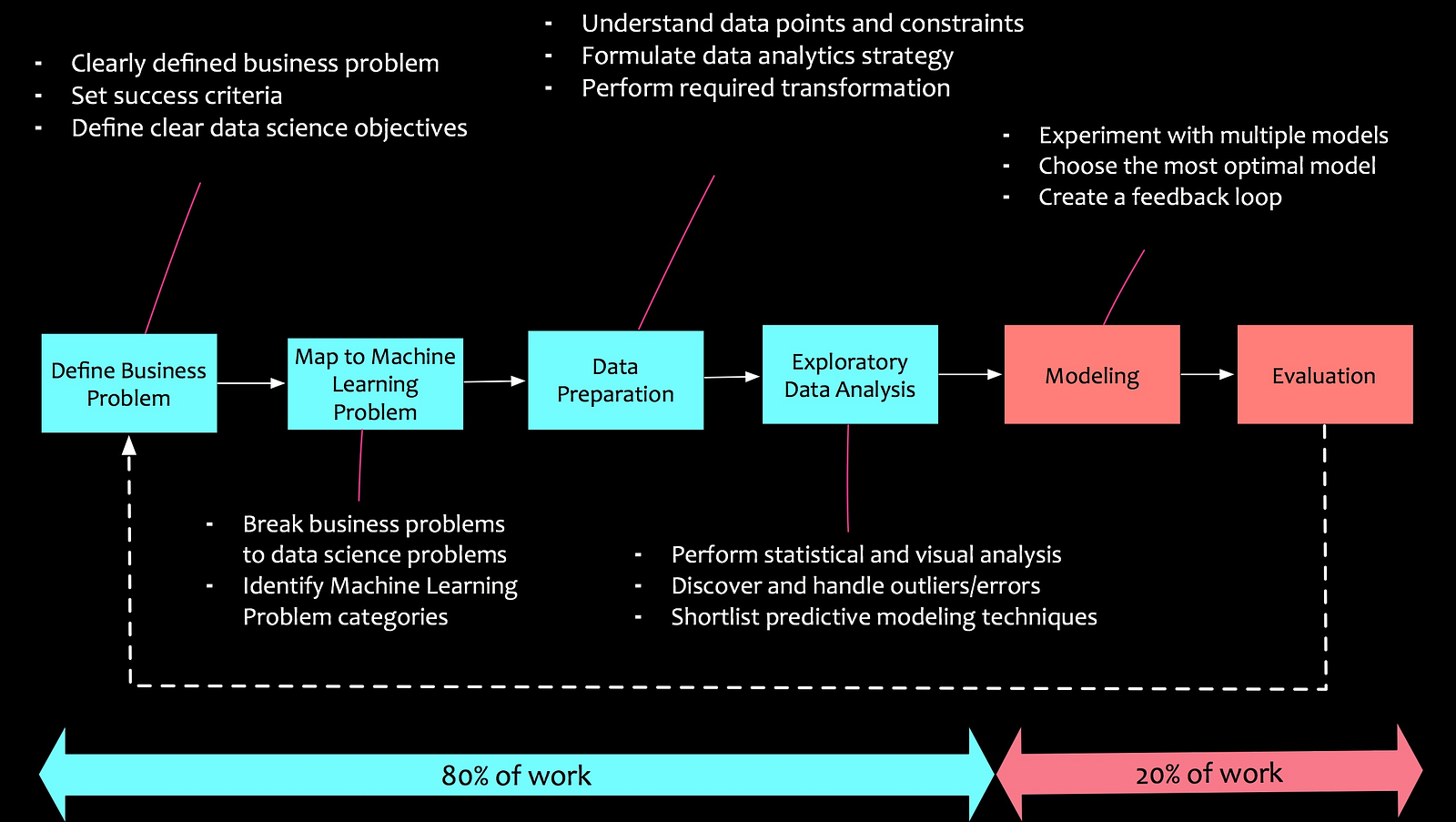
Taking a cue from principle #2, let me now emphasize on the process part of data science. Following are the stages of a typical data science project:
1. Define Business Problem
Albert Einstein once quoted “Everything should be made as simple as possible, but not simpler”. This quote is the crux of defining the business problem. Problem statements need to be developed and framed. Clear success criteria need to be established. In my experience, business teams are too busy with their operational tasks at hand. It doesn’t mean that they don’t have challenges that need to be addressed. Brainstorming sessions, workshops, and interviews can help to uncover these challenges and develop hypotheses. Let me illustrate this with an example. Let us assume that a telco company has seen a decline in their year-on-year revenue due to a reduction in their customer base. In this scenario, the business problem may be defined as:
- The company need grow the customer base by targeting new segments and reducing customer churn.
2. Decompose To Machine Learning Tasks
The business problem, once defined, needs to be decomposed to machine learning tasks. Let’s elaborate on the example that we have set above. If the organization needs to grow our the customer base by targeting new segments and reducing customer churn, how can we decompose it into machine learning problems? Following is an example of decomposition:
- Reduce the customer churn by x %.
- Identify new customer segments for targeted marketing.
3. Data Preparation
Once we have defined the business problem and decomposed into machine learning problems, we need to dive deeper into the data. Data understanding should be explicit to the problem at hand. It should help us with to develop right kind of strategies for analysis. Key things to note is the source of data, quality of data, data bias, etc.
4. Exploratory Data Analysis
A cosmonaut traverses through the unknowns of the cosmos. Similarly, a data scientist traverses through the unknowns of the patterns in the data, peeks into the intrigues of its characteristics and formulates the unexplored. Exploratory data analysis (EDA) is an exciting task. We get to understand the data better, investigate the nuances, discover hidden patterns, develop new features and formulate modeling strategies.
5. Modelling
After EDA, we move on to the modeling phase. Here, based on our specific machine learning problems, we apply useful algorithms like regressions, decision trees, random forests, etc.
6. Deployment and Evaluation
Finally, the developed models are deployed. They are continuously monitored to observe how they behaved in the real world and calibrated accordingly.
Typically, the modeling and deployment part is only 20% of the work. 80% of the work is getting your hands dirty with data, exploring the data and understanding it.
Machine Learning Problem Types
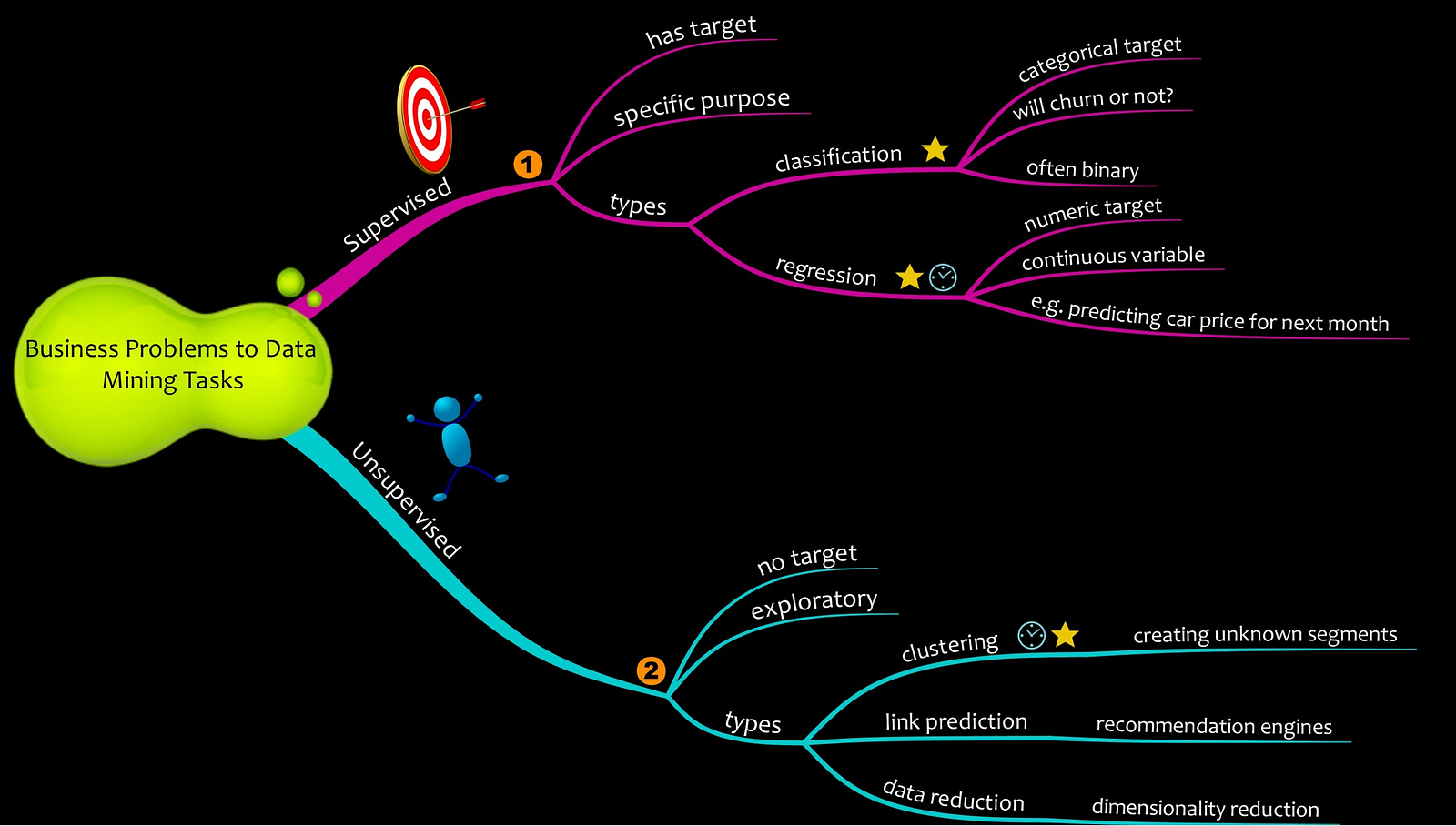
In general, machine learning has two kinds of tasks:
Supervised Learning
Supervised learning is a type of machine learning task where there is a defined target. Conceptually, a modeler will supervise the machine learning model to achieve a particular goal. Supervised Learning can be further classified into two types:
- Regression: Regression is the workhorse of machine learning tasks. They are used to estimate or predict a numerical variable. Few examples of regression models can be:
- What is the estimate of the potential revenue next quarter?
- How many deals can I close next year?
- Classification: As the name suggests, classification models classify something. It is estimated which bucket something is best suited. Classification models are frequently used in all types of applications. Few examples of classification models are:
- Spam filtering is a popular implementation of a classification model. Here every incoming e-mail is classified as spam or not spam based on certain characteristics.
- Churn prediction is another important application of classification models. Churn models used widely in telcos to classify whether a given customer will churn (i.e. cease to use the service) or not.
Unsupervised Learning
Unsupervised learning is a class of machine learning task where there are no targets. Since unsupervised learning doesn’t have any specified target, the result that they churn out may be sometimes difficult to interpret. There are a lot of types of unsupervised learning tasks. The key ones are:
- Clustering: Clustering is a process of group similar things together. Customer segmentation uses clustering methods.
- Association: Association is a method of finding products that are frequently matched with each other. Market Basket analysis in retail uses association method to bundle products together.
- Link Prediction: Link prediction is used to find the connection between data items. Recommendation engines employed by Facebook, Amazon and Netflix heavily use link prediction algorithms to recommend us friends, items to purchase and movies respectively.
- Data Reduction: Data reduction methods are used to simplify data set from a lot of features to a few features. It takes a large data set with many attributes and finds ways to express them in terms of fewer attributes.
Machine Learning Task to Models to Algorithm
Once we have broken down business problems into machine learning tasks, one or many algorithms can solve a given machine learning task. Typically, the model is trained on multiple algorithms. The algorithm or set of algorithms that provide the best result is chosen for deployment.
Azure Machine Learning has more than 30 pre-built algorithms that can be used for training machine learning models.

Azure Machine Learning cheat-sheet will help to navigate through it.
Conclusion
Data Science is a broad field. It is an exciting field. It is an art. It is a science. In this article, we have just explored the surface of the iceberg. The “hows” will be futile if the “whys” are not known. In the subsequent articles, we will explore the “hows” of machine learning.
No comments:
Post a Comment