PinSage: A New Graph Convolutional Neural Network for Web-Scale Recommender Systems
Ruining He | Pinterest engineer, Pinterest Labs
Deep learning methods have achieved unprecedented performance on a broad range of machine learning and artificial intelligence tasks like visual recognition, speech recognition and machine translation. However, despite amazing progress, deep learning research has mainly focused on data defined on Euclidean domains, such as grids (e.g., images) and sequences (e.g., speech, text). Nonetheless, most interesting data, and challenges, are defined on non-Euclidean domains such as graphs, manifolds and recommender systems. The main question is, how to define basic deep learning operations for such complex data types. With a growing and global service, we don’t have the option of a system that won’t scale for everyday use. Our answer came in the form of PinSage, a random-walk Graph Convolutional Network capable of learning embeddings for nodes in web-scale graphs containing billions of objects.
Here we’ll show how we can create high-quality embeddings (i.e. dense vector representations) of nodes (e.g., Pins/images) connected into a large graph. The benefit of our approach is that by borrowing information from nearby nodes/Pins the resulting embedding of a node becomes more accurate and more robust. For example, a bed rail Pin might look like a garden fence, but gates and beds are rarely adjacent in the graph. Our model relies on this graph information to provide the context and allows us to disambiguate Pins that are (visually) similar, but semantically different.
To our knowledge, this is the largest application of deep graph embeddings to date and paves the way for a new generation of web-scale recommender systems based on graph convolutional architectures.
Background
One of Pinterest’s greatest values is our ability to make visual recommendations based on taste by taking into account the context added by hundreds of millions of users, and then to help people discover ideas and products that match their interests. As the number of people using Pinterest grows beyond 200M+ MAU, and the number of objects saved has crossed 100B, we must continuously build technology to not only keep up, but make recommendations smarter.
As a content discovery application, people use Pinterest to save and organize Pins, which are visual bookmarks to online content (recipes, clothes, products, etc.) onto boards. We model the Pinterest environment as a bipartite graph consisting of nodes in two disjoint sets, Pins and boards. Each Pin is associated with certain information like an image and a set of textual annotations (title, description). Here we aim to generate high-quality embeddings of Pins from our bipartite graph with visual and annotation embeddings as input features.
Pin embeddings are essential to various tasks like recommendation of Pins — including dynamic Pins like those for ads, and shopping — classification, clustering, and even reranking. Such tasks are fundamental to our key services like Related Pins, Search, Shopping, Ads. To achieve our goal of generating high-quality embeddings, we developed a highly-scalable, generic deep learning model called PinSage to extract embeddings of nodes from web-scale graphs. We have successfully applied PinSage on Pinterest data with billions of nodes and tens of billions of edges.
Challenges
In recent years, Graph Convolutional Networks (GCNs) have been proposed to model graphs and seen success on various recommender systems benchmarks. However, these gains on benchmark tasks have yet to be translated to gains in real-world production environments. The main challenge is to scale both the training as well as inference of GCN-based node embeddings to graphs with billions of nodes and tens of billions of edges. Scaling up GCNs is difficult because many of the core assumptions underlying their design are violated when working in a big data environment. For example, all existing GCN-based recommender systems require operating on the full graph Laplacian during training — an assumption that is infeasible when the underlying graph has billions of nodes and whose structure is constantly evolving.
Key Innovations
Here we present a highly-scalable GCN framework that we have developed and deployed in production at Pinterest. Our framework, a random-walk-based GCN named PinSage, operates on a massive graph with three billion nodes and 18 billion edges — a graph that is 10,000X larger than typical applications of GCNs. PinSage leverages several key insights to drastically improve the scalability of GCNs.
1. On-the-fly convolutions
Traditional GCN algorithms perform graph convolutions by multiplying feature matrices by powers of the full graph Laplacian. In contrast, our PinSage algorithm performs efficient, localized convolutions by sampling the neighborhood around a node and dynamically constructing a computation graph. These dynamically constructed computation graphs (Figure 1) specify how to perform a localized convolution around a particular node, and alleviate the need to operate on the entire graph during training.
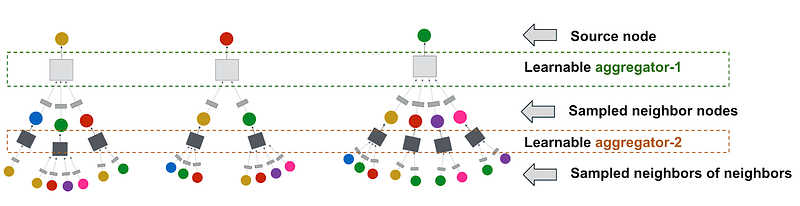
2. Constructing convolutions via random walks
Performing convolutions on full neighborhoods of nodes would result in huge computation graphs, so we resort to sampling. An important innovation in our approach is how we define node neighborhoods, i.e., how we select the set of neighbors to convolve over. Whereas previous GCN approaches simply examine K-hop graph neighborhoods, in PinSage we define importance-based neighborhoods by simulating random walks and selecting the neighbors with the highest visit counts. The advantages of this are two-fold:
- First, it allows our aggregators to take into account the importance of neighbors when aggregating the vector representations of neighbors. We refer to this new approach as importance pooling.
- Second, selecting a fixed number of nodes to aggregate from allows us to control the memory footprint of the algorithm during training.
Our proposed random walk-based approach leads to a 46% performance gain over the traditional K-hop graph neighborhood method in our offline evaluation metrics.
3. Efficient MapReduce inference
Given a fully-trained GCN model, it is still challenging to directly apply the trained model to generate embeddings for all nodes, including those that were not seen during training. Naively computing embeddings for nodes with localized covolutions leads to repeated computations caused by the overlap between K-hop neighborhoods of nodes.
We observe that the bottom-up aggregation (see Figure 1) of node embeddings very nicely lends itself to MapReduce computational model if we decompose each aggregation step across all nodes into three operations in MapReduce, i.e., map, join, and reduce. Simply put, for each aggregation step, we use map to project all nodes to the latent space without any duplicated computations, and then join to send them to the corresponding upper-level nodes on the hierarchy, and finally reduce to perform the aggregation to get the embedding for the upper-level nodes. Our efficient MapReduce-based inference enables generating embeddings for billions of nodes within a few hours on a cluster a few hundred instances.
Offline Evaluation
We implement and evaluate PinSage on Pinterest data — our bipartite Pin-board graph with visual and annotation embeddings as input features. The visual embeddings we use are from a state-of-the-art convolutional neural network deployed at Pinterest. Annotation embeddings are trained using a Word2Vec-based production model at Pinterest, where the context of an annotation consists of other annotations that are associated with each Pin. We evaluate the performance of PinSage against the following content-based deep learning baselines that generate embeddings of Pins:
- Visual embeddings (Visual): Uses nearest neighbors of deep visual embeddings (described above) for recommendations.
- Annotation embeddings (Annot.): Recommends based on nearest neighbors in terms of annotation embeddings (described above).
- Combined embeddings (Combined): Recommends based on concatenating above visual and annotation embeddings, and using a 2-layer multi-layer perceptron to compute embeddings that capture both visual and annotation features. It is trained with the exact same data and loss function as PinSage.
Note that the visual and annotation embeddings we use are state-of-the-art content-based systems currently deployed at Pinterest to generate representations of Pins. We do not compare against other deep learning baselines from the literature simply due to the scale of our problem.
We compare the performance of various approaches in terms of Pin-to-Pin recommendation using Recall as well as Mean Reciprocal Rank (MRR) as the metrics. PinSage outperforms the top baseline by 40% absolute (150% relative) in terms of Recall and also 22% absolute (60% relative) in terms of MRR.
User Studies
We also investigate the effectiveness of PinSage by performing head-to-head comparison between different learned representations. In the study, a user is presented with an image of the query Pin, together with two Pins retrieved by two different recommendation algorithms. The user is then asked to choose which of the two candidate Pins, if either, is more related to the query Pin. Users are instructed to find various correlations between the recommended items and the query item, in aspects such as visual appearance, object category and personal identity. If both recommended items seem equally related, users have the option to choose “equal”. If no consensus is reached among 2/3 of users who rate the same question, we deem the result as inconclusive.
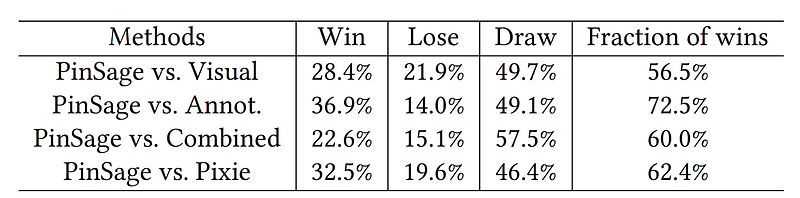
Table 1 shows the results of the head-to-head comparison between PinSage and 4 baselines. Here we include Pixie, a purely graph-based method that uses biased random walks to generate ranking scores by simulating random walks starting at query Pin. Items with top scores are retrieved as recommendations.
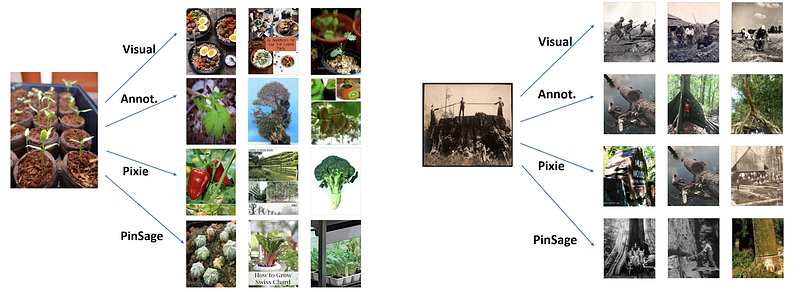
Among items for which the user has an opinion of which is more related, around 60% of the preferred items are recommended by PinSage. Figure 3 gives examples of recommendations and illustrates strengths and weaknesses of the different methods. Ultimately, combining both visual, textual and graph information, PinSage is able to find relevant items that are both visually and topically similar to the query item.
A/B Test
We launched A/B experiments in both Home Feed and Related Pin Ads and compared against annotation embedding-based baseline and observed around 30% relative improvement in terms of user engagement rates.
No comments:
Post a Comment