How to train Machine Learning models in the cloud using Cloud ML Engine
Published by: Chris Rawles
And how to artfully write a
task.py using the docopt package
Training ML models in the cloud makes a lot of sense. Why? Among many reasons, it allows you to train on large amounts of data with plentiful compute and perhaps train many models in parallel. Plus it’s not hard to do! On Google Cloud Platform, you can use Cloud ML Engine to train machine learning models in TensorFlow and other Python ML libraries (such as scikit-learn) without having to manage any infrastructure. In order to do this, you will need to put your code into a Python package (i.e. add
setup.py and __init__.py files). In addition, it is a best practice to organize your code into a model.py and task.py. In this blog post, I will step you through what this involves.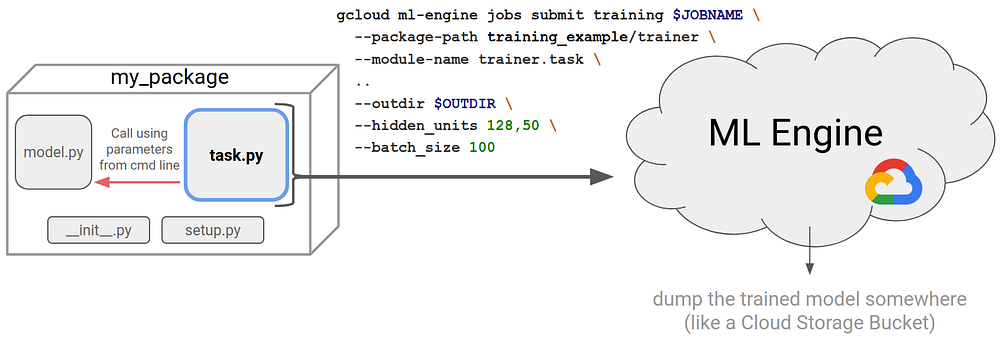
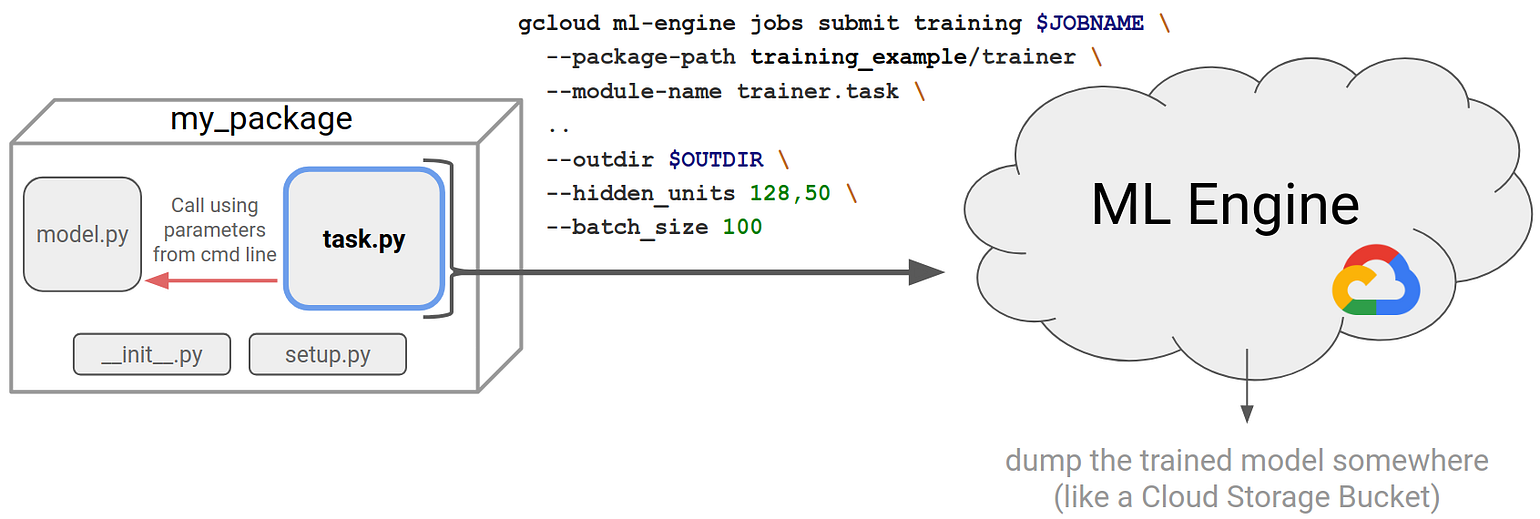
task.py is the file actually executed by ML Engine and it references the model logic located in model.py.
The
task.py file
As a teacher, one of the first things I see students, particularly those newer to Python, get hung up on is creating a
task.py file. Although it’s technically optional (see below), it’s highly recommended because it allows you to separate hyperparameters from the model logic (located in model.py). It’s usually the actual file that is called by ML engine and its purpose is twofold:- Reads and parses model parameters, like location of the training data and output model, # hidden layers, batch size, etc.
- Calls the model training logic located in
model.pywith said parameters import argparse import model # Your model.py file. if __name__ == '__main__': parser = argparse.ArgumentParser() # Input Arguments parser.add_argument( '--train_data_paths', help = 'GCS or local path to training data', required = True ) # Training arguments parser.add_argument( '--batch_size', help = 'Batch size', type = int, default = 150 ) parser.add_argument( '--hidden_units', help = 'Hidden layer sizes', nargs = '+', type = int, default = [128, 32, 4] ) parser.add_argument( '--output_dir', help = 'GCS location to write checkpoints and export models', required = True ) args = parser.parse_args() # Assign model variables to commandline arguments model.TRAIN_PATHS = args.train_data_paths model.BATCH_SIZE = args.batch_size model.HIDDEN_UNITS = args.hidden_units model.OUTPUT_DIR = args.output_dir # Run the training job model.train_and_evaluate() - There are many different ways you can write a
task.pyfile — there are even different names you can give it. In fact thetask.pyandmodel.pyconvention is merely that — a convention. We could have calledtask.pyaReallyCoolArgument_parser.pyandmodel.pyvery_deeeep_model.py.We could even combine these two entities into a single file that does argument parsing and trains a model. ML Engine doesn’t care as long as you arrange your code into a Python package (i.e. it must containsetup.pyand__init__.py). But, stick with the convention of two files namedtask.pyandmodel.pyinside a trainer folder (more details below) that house your argument parsing and model logic, respectively.Check out the Cloud ML samples and Cloud ML training repos for full examples of using Cloud ML Engine and examples ofmodel.pyandtask.pyfiles.Writing cleantask.pyfiles using docoptAlthough many people use argparse, the standard Python library for parsing command-line arguments, I prefer to write mytask.pyfiles using the docoptpackage. Why? Because it’s the most concise way to write a documentedtask.py. In fact, pretty much the only thing you write is your program’s usage message (i.e. the help message) and docopt takes care of the rest. Based on the usage message you write in the module’s doc string (Python will call this__doc__), you calldocopt(__doc__), which generates an argument parser for you based on the format you specify in the doc string. Here is the above example using docopt:"""Run a training job on Cloud ML Engine for a given use case. Usage: trainer.task --train_data_paths <train_data_paths> --output_dir <outdir> [--batch_size <batch_size>] [--hidden_units <hidden_units>] Options: -h --help Show this screen. --batch_size <batch_size> Integer value indiciating batch size [default: 150] --hidden_units <hidden_units> CSV seperated integers indicating hidden layer sizes. For a fully connected model.', [default: 100] """ from docopt import docopt import model # Your model.py file. if __name__ == '__main__': arguments = docopt(__doc__) # Assign model variables to commandline arguments model.TRAIN_PATHS = arguments['<train_data_paths>'] model.BATCH_SIZE = int(arguments['--batch_size']) model.HIDDEN_UNITS = [int(h) for h in arguments['--hidden_units'].split(',')] model.OUTPUT_DIR = arguments['<outdir>'] # Run the training job model.train_and_evaluate() Pretty nice, right? Let me break it down. The first block of code is the usage for yourtask.py. If you call it with no arguments or incorrectly calltask.pythis will display to the user.The linearguments = docopt(__doc__)parses the usage pattern (“Usage: …”) and option descriptions (lines starting with dash “-”) from the help string and ensures that the program invocation matches the usage pattern.The final section assigns these parameters tomodel.pyvariables and then executes the training and evaluation.Let’s run a job. Remember thetask.pyis part of a family of files, called a Python package. In practice you will spend the bulk of your time writing themodel.pyfile, a little time creating thetask.py file, and the rest is basically boilerplate.training_example # root directory setup.py # says how to install your package trainer # package name, “trainer” is convention model.py task.py __init__.py # Python convention indicating this is a packageBecause we are using docopt, which is not part of the standard library, we must add it tosetup.py, so we insert an additional line intosetup.py:from setuptools import find_packages from setuptools import setup REQUIRED_PACKAGES = ['docopt'] setup( name='my-package', version='0.1', author = 'Chris Rawles', author_email = 'chris.rawles@some-domain.com', install_requires=REQUIRED_PACKAGES, packages=find_packages(), description='An example package for training on Cloud ML Engine.') This will tell Cloud ML Engine to install docopt by runningpip install docoptwhen we submit a job to the cloud.Finally once we have our files in the above structure we can submit a job to ML Engine. Before we do that, let’s first test our package locally usingpython -mand thenml-engine local predict. These two steps, while optional, can help you debug and test your packages functionality before submitting to the cloud. You typically do this on a tiny data set or just a very limited number of training steps.Step 1: local run using
python -mIn [1]:%%bash TRAIN_DATA_PATHS=path/to/training/data OUTPUT_DIR=path/to/output/location export PYTHONPATH=${PYTHONPATH}:${PWD}/training_example python -m trainer.docopt_task --train_data_paths $TRAIN_DATA_PATHS\ --output_dir $OUTPUT_DIR\ --batch_size 100\ --hidden_units 50,25,10
Step 2: local run using
ml-engine local trainVery useful for debuggingML EngineparametersIn [ ]:%%bash TRAIN_DATA_PATHS=path/to/training/data OUTPUT_DIR=path/to/output/location JOBNAME=my_ml_job_$(date -u +%y%m%d_%H%M%S) REGION='us-central1' BUCKET='my-bucket' gcloud ml-engine local train\ --package-path=$PWD/training_example/trainer \ --module-name=trainer.task \ -- \ # Required. Seperates ML engine params from package params. --train_data_paths $TRAIN_DATA_PATHS \ --output_dir $OUTPUT_DIR\ --batch_size 100\ --hidden_units 50,25,10
Once we have tested our model locally we will submit our job to ML Engine usinggcloud ml-engine jobs submit trainingTrain on the cloud using
ml-engineNote the arguments toml-engine. Those before the empty--are specific to ML Engine, while those after, namedUSER_ARGS, are for your package.In [ ]:%%bash TRAIN_DATA_PATHS=path/to/training/data OUTPUT_DIR=path/to/output/location JOBNAME=my_ml_job_$(date -u +%y%m%d_%H%M%S) REGION='us-central1' BUCKET='my-bucket-name' gcloud ml-engine jobs submit training $JOBNAME \ --package-path=$PWD/training_example/trainer \ --module-name=trainer.task \ --region=$REGION \ --staging-bucket=gs://$BUCKET \ --scale-tier=BASIC \ --runtime-version=1.8 \ -- \ # Required. --train_data_paths $TRAIN_DATA_PATHS \ --output_dir $OUTPUT_DIR\ --batch_size 100\ --hidden_units 50,25,10
These two lines are relevant to our discussion:— package-path=$(pwd)/my_model_package/trainer \ — module-name trainer.task
The first line indicates the location of our package name, which we always calltrainer(a convention). The second line indicates, in the trainer package, that we will call the task module (task.py) in the trainer package.ConclusionBy building atask.pywe can process hyperparameters as command line arguments, which allows us to decouple our model logic from hyperparameters. A key benefit is this allows us to easily fire off multiple jobs in parallel using different parameters to determine an optimal hyperparameter set (we can even use the built in hyperparameter tuningservice!). Finally, the docopt package automatically generates a parser for ourtask.pyfile, based on the usage string that the user writes.That’s it! I hope this makes it clear how to submit a ML Engine job and build atask.py. Please leave a clap if you found this helpful so others can find it.Additional Resources
No comments:
Post a Comment